Monday, 25 December 2023
Wednesday, 6 December 2023
life cycle of a thread notes
A thread life cycle is always in one of these five states. It can move from one state to another state. In Java, the life cycle of thread has five states.
1. Newborn State
2. Runnable State
3. Running State
4. Blocked State
5. Dead State
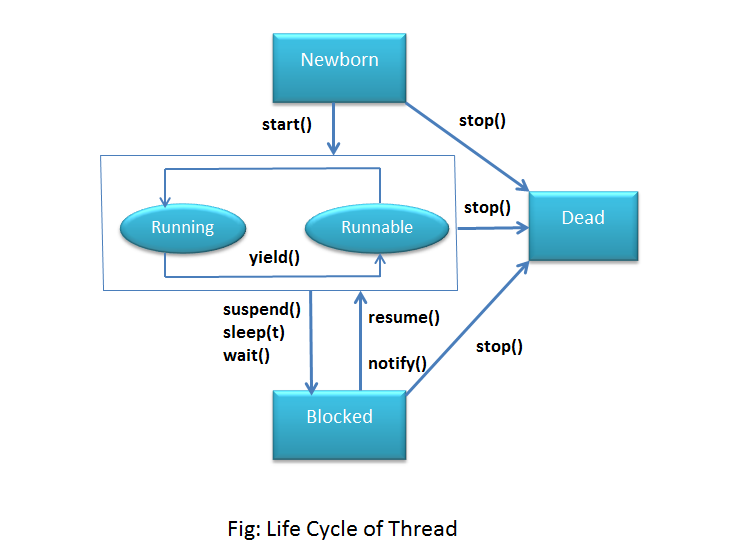
New : A thread begins its life cycle in the new state. It remains in this state until the start() method is called on it.
Thread t = new Thread();Runnable : After invocation of start() method on new thread, the thread becomes runnable.
Thread t = new Thread();
t.start();Running : A thread is in running state if the thread scheduler has selected it.
t1.isAlive() - The isAlive() method returns true if the thread upon which it is called is still running otherwise it returns false.
Waiting : A thread is in waiting state if it waits for another thread to perform a task. In this stage the thread is still alive.
Example1: t1.join() waiting for t1 to complete its execution
Example2: The state of thread t1 after invoking the method sleep() on it - TIMED_WAITING
Thread.sleep(400);
Terminated : A thread enters the terminated state when it completes its task.
t1.stop()
Tuesday, 28 November 2023
Deadlock Recovery
deadlock recovery techniques like wound-wait and wait-die are used to handle situations where processes are waiting for resources, and a deadlock might occur. Let's break them down:
Wound-Wait:
Think of it like being a bit impatient. If a process needs a resource held by another process, it checks the age or "wound" of the other process.
If the other process is "younger" (started later), then the current process waits.
If the other process is "older" (started earlier), the current process can "wound" it, meaning it can force the older process to release its resources, preventing a deadlock.
Wait-Die:
This approach is more patient. If a process needs a resource held by another process, it checks the age or "age difference" between them.
If the other process is "younger," the current process waits.
If the other process is "older," the current process can "die," meaning it gives up and gets restarted, allowing the older process to continue and preventing a deadlock.
In both cases, the idea is to avoid deadlocks by carefully managing how processes interact.
Sunday, 26 November 2023
Factor analysis, Dimensionality reduction, Predictive analytics, Cluster Analysis, Decision Tree, Types of Decision Trees notes
Factor analysis: in factor analysis, latent variables are turned into factors i.e, they are reduced according to their functionality
Example waiting time, cleanliness, healthy and taste are latent variables
waiting time, cleanliness are service factors
healthy and taste are food experience factor
In a hotel or restaurant these latent variables are reduced to factors.
Descriptive analysis is very important in the sense of model building
Merits of factor analysis:
1. reduces amount of data
2. easy categorization
3. uses statistical methods
4. very important in model building
5. data is very easy to interpret as there are no outliers
6. is important descriptive analysis technique
Predictive analytics: is when we retrieve the unknown or future data with the help of past/current data
There are 4 types of predictive analysis
1. classification
2. Prediction
3. Regression
4. Time series
These types are used in different situations accordingly
Dimensionality reduction: when there is data with high dimensionality working with it becomes difficult and tedious task.
to remove this we perform data reduction step in KDD process
Dimensionality reduction is a part of data reduction
Some dimensionality reduction:
1. Data cube: data is arranged in cube form to ensure there are less dimensions
2. Numerosity: we can apply rank to groups of data
3. Feature selection: we need to find appropriate features using filtering, morphing etc
4. Normalization: to make all the data in same range or interval
Lazy Learning: Lazy learning is a technique where we give a model some rules and testing criteria. But it only executes them when the data is given to them or from their neighbours
if we give data suppose a=2 and b=3 then only it learns from the formula otherwise it wont
it is useful when we have TB of data and we cant test all of it.
kNN is a lazy learning algorithm
Cluster Analysis
Cluster analysis is a kind of descriptive analysis where we group or cluster similar kind of data.
it is helpful for large amounts of unstructured data
it is used to further analysis and building models
Although there are different types of cluster analysis but the most popular ones are
1. partitioning clusters
2. hierarchical
3. Density Based
4. Grid Based
1. Partitioning Methods: as the name suggest partitioning methods involves partitioning a data set and performing some analysis or methods or formulas to derive the cluster.
K- means and K- medoids are Partitioning methods
2. Hierarchical Methods: As the name suggests we need to form a hierarchy and then we can form one cluster.
Agglomerative and Divisive are popular hierarchical methods
3. Density Methods: When we assign some density to the data points and combine them by their density. DBScan is one of the popular density based clustering technique
4. Grid Based: in this method, we assign the density to the cluster and then store them in the form of a rectangular grid with cells
Then we apply decision tree and apply levels
Higher level cells are stored in one cluster and lower level in one
In cluster analysis, we need to choose the appropriate cluster technique for the datasets
Decision Tree: Here in this below example,
weather is root node
humidity and speed are attributes/ columns
yes or no are class labels
This example shows if a child can play outside or not.
In decision tree, rectangle represents attributes/ columns
ellipse represents class labels
The main purpose of decision tree is to extract the rules for classification.
Example: if weather = sunny and humidity = normal then play = yes
if weather = cloudy then play = yes
id weather = windy and speed = low then play = yes
Types of Decision Trees
1) un weighted decision tree: when there is no weight on any nodes of the decision tree, i.e, there are no biases in decision tree
2. weighted decision tree:
3. binary decision tree: where there are only two attributes or labels in a tree
4. Random forest: n number of decision trees combined
Functions and Files in python
Function is used to run a block of code
Syntax:
def function_name(arguments):
statements
return
def - declaration of the function
function_name: it refers to the name of the function
arguments: values passed to the function
statement - block of code to run program
return - it is used to return the value. It is sometimes used and sometimes not used
Note: once return is executed, it is end of the function
Function call: We can call the function by using function name. once the function is called the execution takes place to the definition of the function.
Syntax: def greet()
def greet():
statements
#calling the function
greet()
Example:
def add_numbers(a=8, b=6):
sum = a+b
print(sum)
#call the function
add_numbers(2,3)
Ouput:
5
Files in Python
There are different operations on file
1. creating a file: fp = open('file.txt', 'w') or fp = open('file.txt', 'a')
2. opening a file : fp = open('file.txt', 'w') or fp = open('file.txt', 'a') or fp = open('file.txt', 'r')
3. reading fp = open('file.txt', 'r')
4. writing to file fp = open('file.txt', 'w')
5. closing the file fp.close()
6. appending to a file fp = open('file.txt', 'a')
Big Data Analytics notes
Big data is large amount of complex data which is increasing rapidly. This data can be of any type and this data is inconsistent in nature. This data cannot be processed through traditional methods.
Characteristics of Big data
There are four main characteristics of big data
1) volume: big data can be very large
2) variety: big data can be of any data type
3) veracity: big data can be inconsistent at times
4) velocity: the speed at which big data is generated is fast
Importance of big data
in todays generation with 8 billion population, big data plays an important role.
1) In business, big data can generate meaningful insights through big data tools to increase customer satisfaction.
Ex: if there is an company, it can use big data to analyze customer behavior and recommend relevant products.
2) Big data also plays an important role in science
large number of test can be analyzed very effectively using big data
3)Personal use: big data can also be useful to us
Ex: like in Spotify , we have each persons yearly recap, where it shows what kind of music, we listened to in that year.
Applications of Big Data
Big data is used and applied in almost every sector now - a- days.
This can be made possible through tools like hadoop.
Some of the applications of big data are
1) In hospitals, to manage large amount of patients
2) in business, to bring out meaningful insights
3) in education institutions to evaluate student performance
4) in social media
5) search engine
6) online shopping
7) in scientific research
Data sources: are those sources from which we can acquire big data
internal data source: these sources use sensor technologies and are commonly used in organizations i.e, these sources collect data from their devices, collects data like audio, video, temperature
Ex: mobile phones, IoT devices
third party data sources: where there is any small business that do not have enough money or inventory to have internal data sources, they go for third party data sourcing i.e, they source data using third party technology.
It is commonly seen in small web pages
It collects the data like no. of clicks, opens
Example: google analytics
External data source: these data sources are collected by different source and they are open to be accessed by anyone Ex: social media
Open data sources: these are similar to external sources but open data sources are very complex and are not relevant for us. These can be scientific data or research data or government data
Ex: www.govt.uk
Through these sources we can acquire big data.
Sturctured vs unstructured
Structured : These are in tabular format.
Can be interpreted through machines
easy to analyze and can done through both machines and humands
can use tools like SQL, Oracle
Unstructured: These are in video, audio, image format
can be difficult to interpret through machine
difficult to analyze and can be done through only humans
tools like noSQL, hadoop
PIG architecture
here are 4 main parts of pig
1) parser: it performs semantic checks and checks the syntax in pig scripts. After checking, it converts the pig script to DAG and logical operation format. The parser sends this DAG file to optimizer.
2) optimizer: it takes the DAG input from the parser and applies some functions like projection and push down to delete unnecessary columns. It also optimizes the logical plan of the script. After that it send this optimized DAG file to compiler.
3) compiler: Here, compiler takes optimized DAG file and compiles it. The output of compiler gives a series of map reduce jobs as multi- querying is available in pig compiler. Pig compiler can rearrange the order to execute efficiently
4) execution engine: it takes the final compiled map reduce tasks and executes it.
The other components are
i) Grunt shell: it is like command line interface like pig
ii) Apache pig: where all the libraries are stored
iii) map reduce: where mapping and reducing is done
iv) finally HDFS: where map reduce output is stored.
Hive Architecture
process of hive architecture is similar to apache pig
hive server: hive server takes all the requests from the drivers and serves and sends them to hive driver.
hive driver: hive driver compiles and optimizes the queries that are in DAG format outputs and sends them to execution engine as map reduce task
execution engine: it executes all the map reduce jobs
meta store: it stores all the information about the data present in Hive. It stores meta data about the columns and its information. it serializes and desterilizes data
CLI: Hive command line interface
Hive web UI: It is GUI commonly provided online
Hive Client:
1)Trift Server: it connects all programming languages that support thrift to HIVE
2)JDBC driver: as hive is built on top of map reduce and use java. it connects to java for application purposes
3) ODBC driver: application that connects to HIVE which supports ODBC
Wednesday, 4 October 2023
JQuery DOM attributes
DOM (Document Object Model):
The DOM is like a structure that represents a web page's elements. It's like a map that shows where everything is on the page and helps us interact with them using code.
jQuery is a JavaScript library that makes it easier to work with HTML elements and perform various tasks on a web page, such as handling events, manipulating the DOM (Document Object Model), and making AJAX requests.
DOM attributes:
The id attribute provides a unique name for an element.
The class attribute labels elements as "important."
The src attribute specifies the image file's location.
The href attribute sets the link's destination to
jQuery simplifies the process of working with DOM attributes by providing methods that work consistently across different browsers.
To access and manipulate DOM attributes using jQuery, you typically use methods like .attr(), .addClass(), .removeClass(), .prop(), etc
Example:
<!DOCTYPE html>
<html>
<head>
<title>jQuery DOM Attributes Example</title>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<style>
.highlight {
background-color: yellow;
}
</style>
</head>
<body>
<h1>jQuery DOM Attributes Example</h1>
<img src="image1.jpg" alt="Original Image">
<p id="myParagraph">This is a paragraph with an ID.</p>
<input type="checkbox" id="myCheckbox" checked> Check this box
<button id="addHighlight">Add Highlight</button>
<button id="removeHighlight">Remove Highlight</button>
<button id="changeImage">Change Image</button>
<button id="toggleCheckbox">Toggle Checkbox</button>
<script>
$(document).ready(function(){
// Add Highlight to the paragraph when "Add Highlight" button is clicked
$("#addHighlight").click(function(){
$("#myParagraph").addClass("highlight");
});
// Remove Highlight from the paragraph when "Remove Highlight" button is clicked
$("#removeHighlight").click(function(){
$("#myParagraph").removeClass("highlight");
});
// Change the image source when "Change Image" button is clicked
$("#changeImage").click(function(){
$("img").attr("src", "image2.jpg");
});
// Toggle the checkbox's "checked" property when "Toggle Checkbox" button is clicked
$("#toggleCheckbox").click(function(){
var isChecked = $("#myCheckbox").prop("checked");
$("#myCheckbox").prop("checked", !isChecked);
});
});
</script>
</body>
</html>
User styles sheets
User Style Sheets in CSS:
User style sheets are custom CSS files that a user can create to override or modify the default styles of web pages. They allow users to personalize the appearance of websites according to their preferences.
User style sheets let users control how web pages look on their own browsers.
Users can change colors, fonts, and layout as per their liking.
These style sheets take precedence over the website's styles.
Users can create a file (e.g., user.css) and specify their own styles.
Browser settings enable users to apply their user style sheet.
Example:
Suppose a user wants to increase the font size of all text on websites they visit. They can create a user.css file with the following content:
/* user.css */
body {
font-size: 18px;
}
When they apply this user style sheet through their browser settings, all text on web pages will appear in a larger font, overriding the default styles of websites.
Thursday, 28 September 2023
Principal Component Analysis exam notes
PCA is like a magic tool for making big, confusing data simpler and easier to understand. It helps us find the most important things in the data.
How PCA Works:
1. Data: Think of data as information about people. For example, you might have data about their height, weight, and age.
2. Centering Data: First, we find the "center" of the data by figuring out the average height, weight, and age of all the people. This is like where most people are in terms of these three things.
3. Calculating Relationships: PCA looks at how these things (height, weight, age) are connected to each other. It checks if they move together or separately.
4. Orthogonal Vectors: PCA finds special ways to look at the data, called "orthogonal vectors." These vectors are like arrows pointing in different directions. Each arrow shows a different aspect of the data.
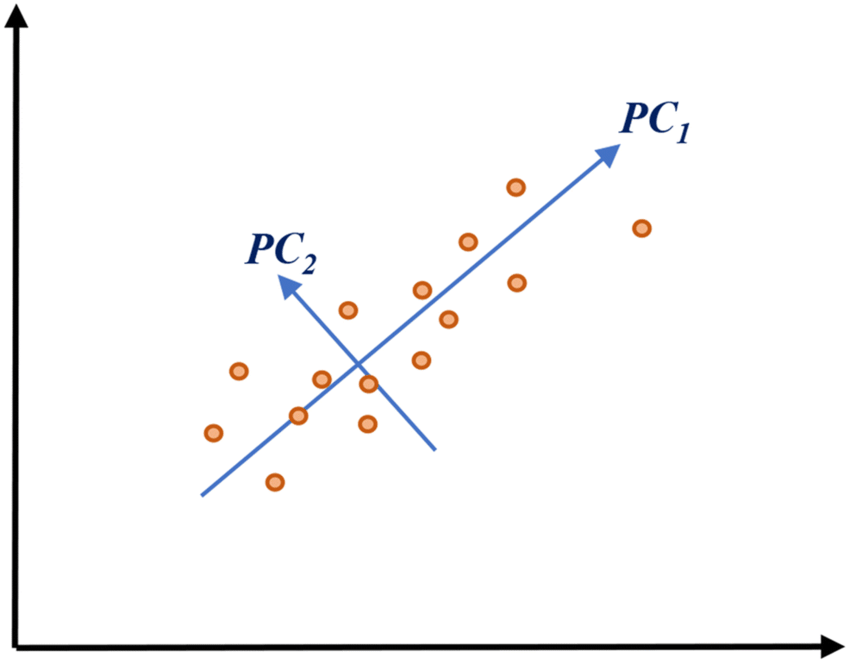
- The first arrow (the first vector) shows us the biggest difference in the data, like the main story.
- The second arrow (the second vector) shows us the second biggest difference, and so on.
5. Eigenvalues and Eigenvectors: The length of each arrow (vector) is called an "eigenvalue." It tells us how important that arrow is. The longer the arrow, the more important it is.
- The direction of each arrow (vector) is called an "eigenvector." It tells us what aspect of the data that arrow represents.
6. Reduced Data: We can change our data into these special ways of looking at it using the arrows. It's like having a new, simpler set of information.
Why Use PCA:
- We use PCA to understand our data better.
- It helps us see the main things that matter and ignore the less important stuff.
In simple words, PCA helps us make our data simpler by finding the most important aspects (represented by orthogonal vectors with long eigenvalues) and understanding them better.
Difference between Q- Learning and Model Based Learning - As told by ChatGPT
Model-Based Learning:
Model of the Environment: In model-based learning, the focus is on building a model or representation of the environment. The robot creates an internal map of the world, including information about states, actions, transitions, and rewards. This map helps the robot simulate its environment.
Planning: Model-based learning involves planning and using the learned model to make decisions. The robot can simulate different actions and predict their outcomes without taking physical actions. This planning aspect helps it choose the best actions to reach its goals efficiently.
Data-Intensive: It requires a lot of data collection and modeling effort. The robot needs to explore the environment extensively to build an accurate model, which can be data-intensive and time-consuming.
Use of a Learned Model: The robot relies on its learned model to make decisions about actions. It doesn't directly use Q-values or learn from rewards through trial and error.
Q-Learning:
Q-Values: In Q-learning, the focus is on learning Q-values, which represent the expected cumulative rewards for taking a specific action in a particular state. The robot maintains a Q-table, where each entry corresponds to a state-action pair.
Trial and Error: Q-learning is based on trial and error. The robot explores the environment by taking actions and learning from the rewards it receives. It doesn't necessarily build a detailed model of the environment.
Action Selection: Q-learning involves selecting actions based on the Q-values in the Q-table. The robot chooses the action with the highest Q-value for its current state, emphasizing exploitation of learned information.
Data-Efficient: Q-learning can be more data-efficient than model-based learning because it directly learns from rewards during exploration without needing to build an explicit model.
In summary, the key difference lies in how they approach learning and decision-making:
- Model-based learning focuses on creating a detailed model of the environment and using it for simulation and planning.
- Q-learning focuses on learning the values of actions directly from rewards through trial and error, without necessarily building a detailed model.
The choice between these approaches depends on the specific problem and the available resources for learning and exploration.
Model Based Reinforcement Learning example
Model Based Reinforcement Learning example:
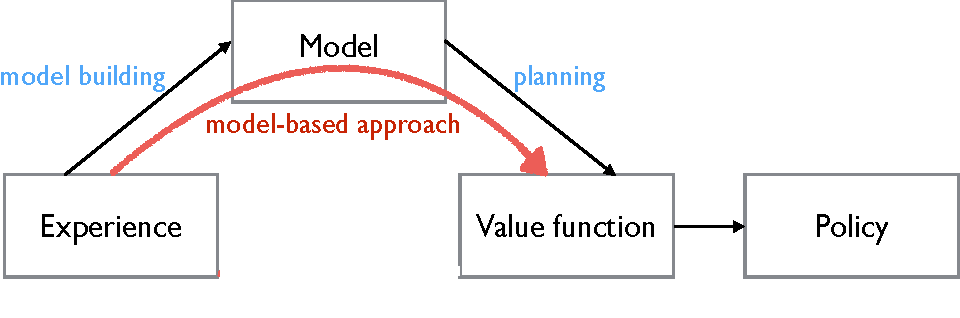
Source: https://www.google.com/url?sa=i&url=https%3A%2F%2Fmedium.com%2Fanalytics-vidhya%2Fmodel-based-offline-reinforcement-learning-morel-f5cd991d9fd5&psig=AOvVaw17zqlCJPf9ASKzbC2CkiVg&ust=1675731090336000&source=images&cd=vfe&ved=0CBEQjhxqFwoTCOCm6PTW__wCFQAAAAAdAAAAABAE
Example: Robot in a Maze
- Imagine a robot in a maze trying to find a treasure.
Experience:
- The robot explores the maze, moving around and gathering experience.
- It remembers which actions it took, where it went, and the rewards it received.
Model:
- The robot builds a "map" or model of the maze.
- This model includes information about where walls are, possible paths, and what might happen at each location.
- The model helps the robot understand the maze better.
Value Function:
- The robot keeps track of values for different states in the maze.
- These values represent how good it is to be in a particular state.
- For example, finding the treasure has a high value.
Policy:
- The robot uses its value function and model to create a "policy."
- A policy is like a set of rules that tell the robot which actions to take in different situations.
- It helps the robot decide where to go to maximize its rewards.
Tables:
- The robot maintains tables to store information.
- One table keeps track of its experiences.
Experience Table:
| State | Action | Next State | Reward |
|------- |-------- |------------|--------|
| Start | Move Up | Wall | -1 |
| ... | ... | ... | ... |
| Treasure | Grab | Exit | +100 |
- Another table stores the value function, showing how good each state is.
Value Function Table:
| State | Value |
|------- |------- |
| Start | 0 |
| ... | ... |
| Treasure | 100 |
How It Works:
1. The robot starts in the maze, taking actions and learning from rewards.
2. It uses the experiences to update its model of the maze.
3. It calculates values for each state using its value function.
4. With the model and values, it creates a policy for making decisions.
5. The robot follows the policy to find the treasure efficiently.
In this example, model-based reinforcement learning helps the robot build a model of the maze, use it to make decisions, and find the treasure while keeping things simple.
Q- Learning With a simple example
Example: Student's Study Strategy with Q-Learning
Imagine a student who wants to maximize their grades by studying effectively.
Goal: get maximum grade
Q-Values:
- Q-values represent the perceived effectiveness of different study strategies.
- Each study strategy has a Q-value indicating how good it is for achieving high grades.
States:
- States represent the student's current situation, like the subject they're studying and their current knowledge level.
Actions:
- Actions are the various study strategies the student can choose from, such as "Read the textbook," "Take practice quizzes," "Watch video lectures," and "Review notes."
Q-Table:
- We maintain a Q-table to track Q-values for each state-action pair.
Initial Q-Table:
Let's start with an initial Q-table:
| State (Subject, Knowledge Level) | Action (Study Strategy) | Q-Value (Effectiveness) |
|--------------------------------- |------------------------- |--------------------------|
| Math, Novice | Read the textbook | 0 |
| Math, Novice | Take practice quizzes | 0 |
| ... | ... | ... |
| History, Intermediate | Review notes | 0 |
Learning Process:
1. Initial Values: Initially, all Q-values in the table are set to 0.
2. Studying: The student studies various subjects and chooses study strategies.
3. Grades: After each exam, the student receives a grade (reward).
4. Updating Q-Values: After receiving a grade, the student updates the Q-values for the state-action pairs involved in their study strategy.
- For instance, if they studied math as a novice and took practice quizzes, and they received an excellent grade, they increase the Q-value for "Take practice quizzes" when in the state (Math, Novice) because they learned that this strategy is effective.
Updated Q-Table:
| State (Subject, Knowledge Level) | Action (Study Strategy) | Q-Value (Effectiveness) |
|--------------------------------- |------------------------- |--------------------------|
| Math, Novice | Read the textbook | 0 |
| Math, Novice | Take practice quizzes | 100 |
| ... | ... | ... |
| History, Intermediate | Review notes | 0 |
5. Choosing Actions: As the student continues to study different subjects and use study strategies, they refer to the Q-table to decide which strategy to use. They select the strategy with the highest Q-value for their current situation.
6. Learning Continues: The student repeats this process, studying, receiving grades, and updating Q-values. Over time, they become better at selecting effective study strategies to maximize their grades.
In this Q-learning example, the student's goal is to learn the optimal study strategies for each subject and knowledge level to maximize their grades. They achieve this by updating Q-values based on their exam results and using these values to make decisions about study strategies. Over time, the student becomes more proficient at studying effectively.