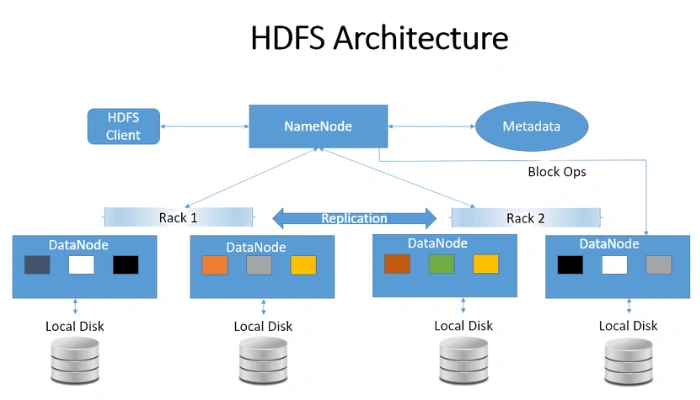
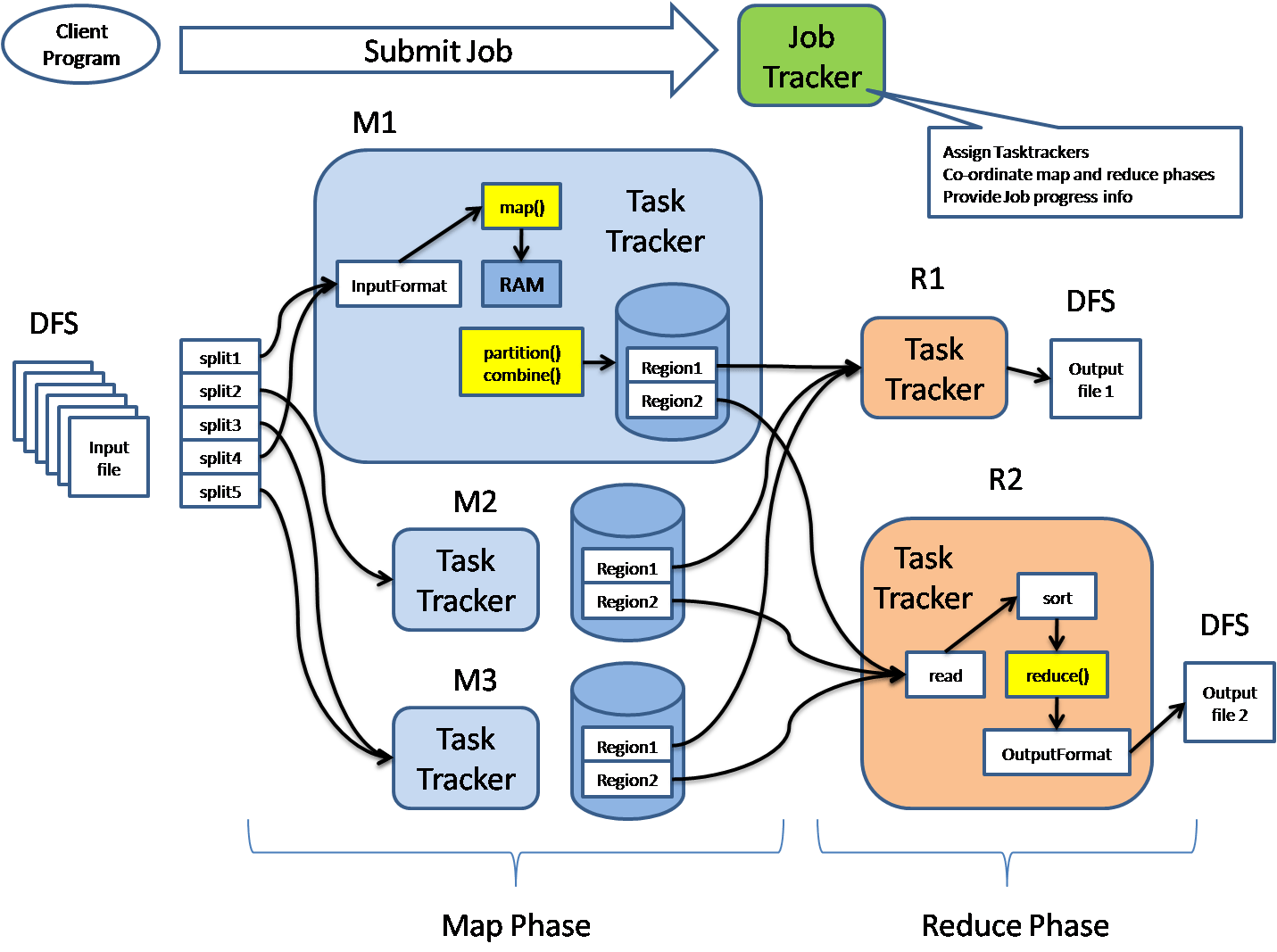
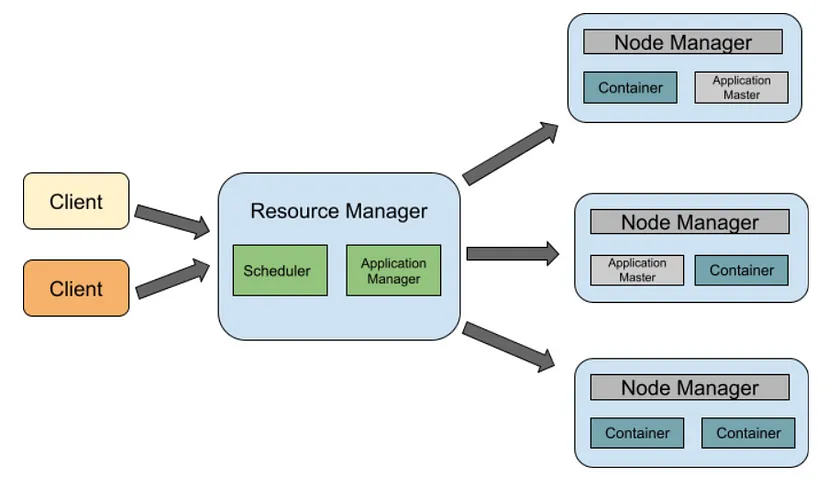
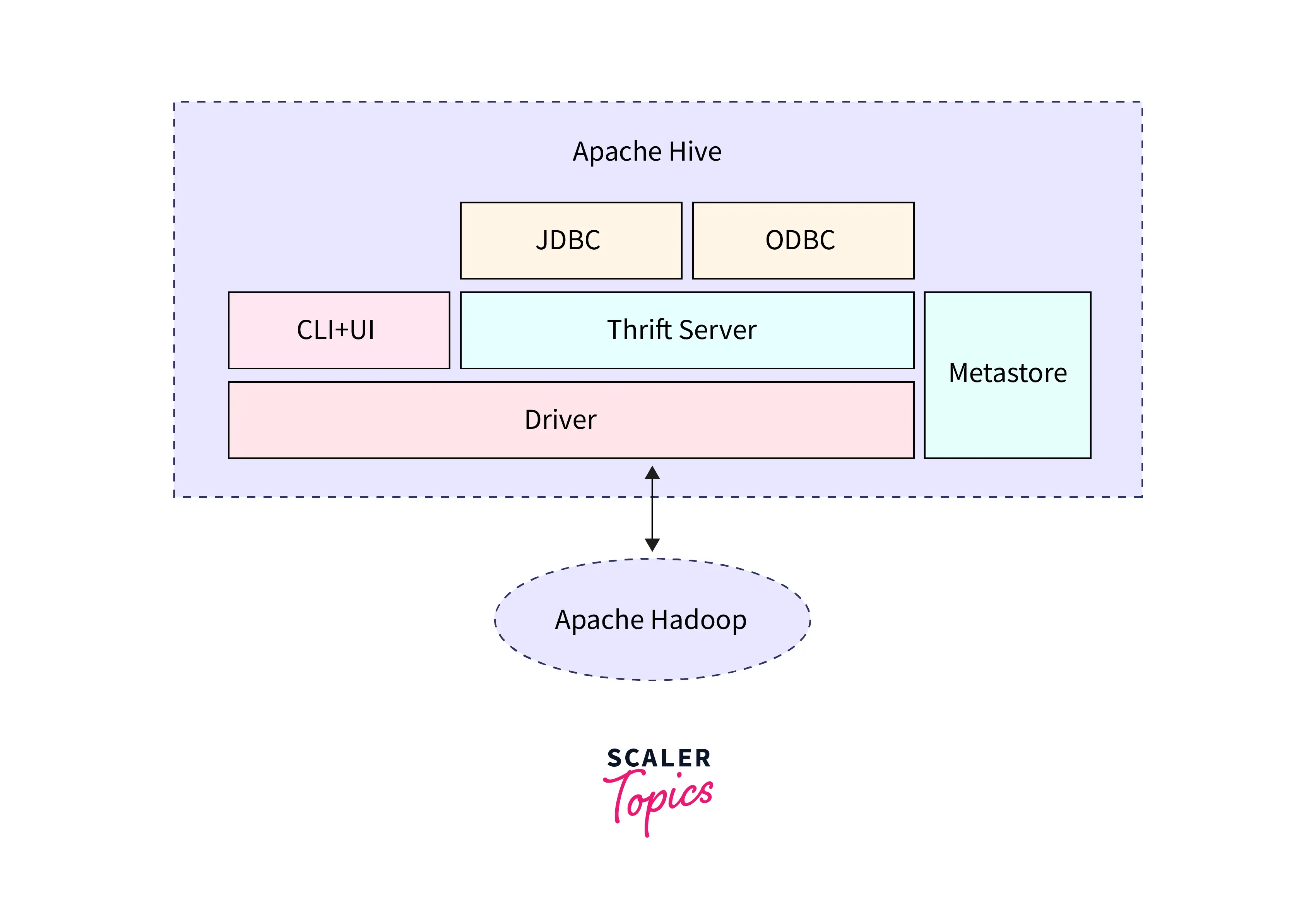
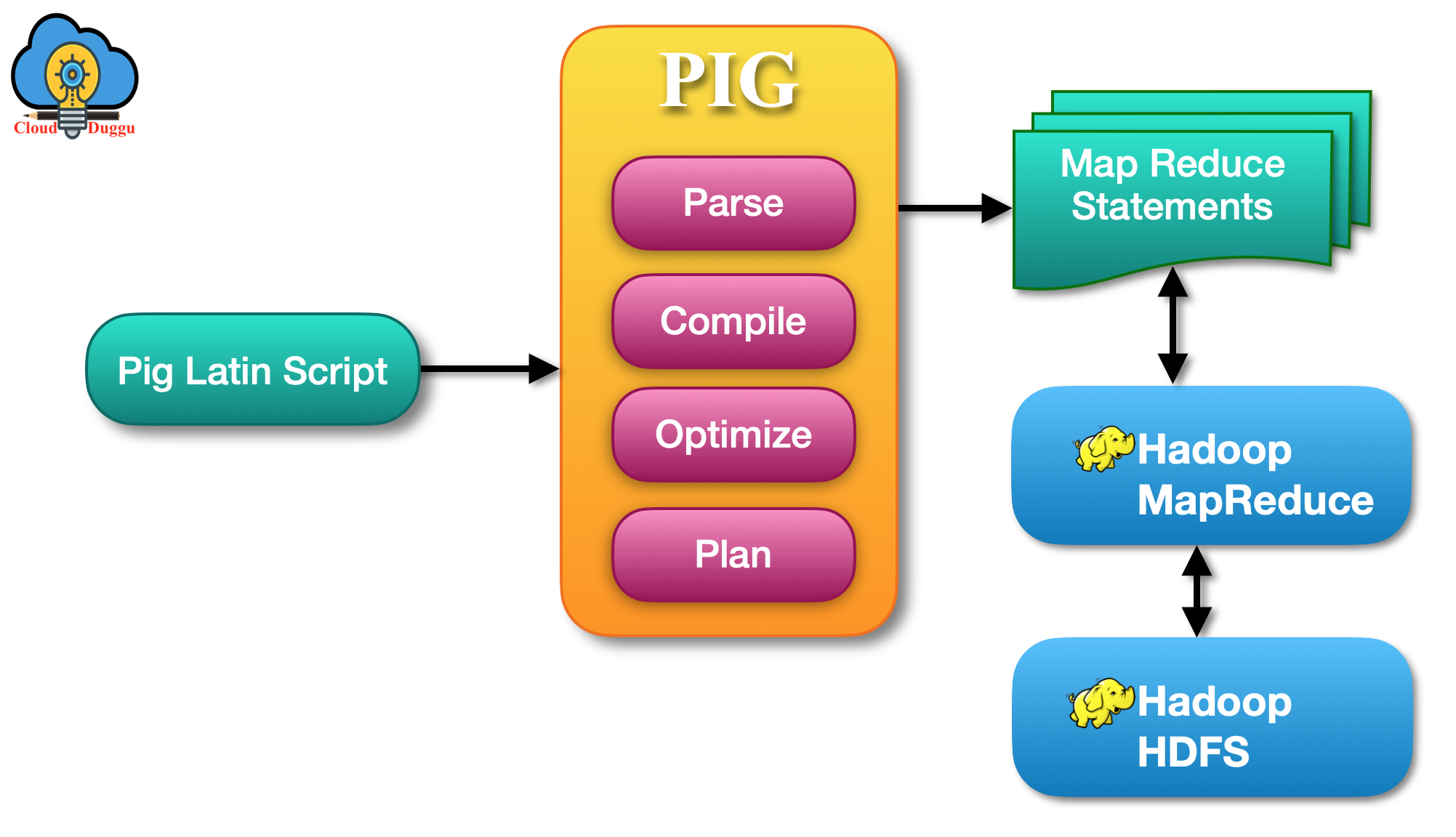
Project 1: E-commerce Sales Trend Analysis & Forecasting
Real-world use: Flipkart/Amazon predict monthly sales.
How to Start Today:
1. Download “Retail Sales Dataset” from Kaggle (1.5 GB+)
2. Upload to HDFS
3. Clean with Hive/MapReduce
4. Export to R
library(forecast)
sales <- read.csv("hadoop_export_sales.csv")
ts_data <- ts(sales$MonthlySales, frequency=12)
forecast <- forecast(ts_data, h=6)
plot(forecast)Project 2: Movie Recommendation System (Most Popular!)
Real-world use: Netflix “You may also like” using MovieLens dataset (1M+ ratings).
Simple Architecture (5 Easy Steps)
- Storage Layer → Raw ratings in Hadoop HDFS
- Processing Layer → MapReduce or Hive creates User-Item matrix
- Export Layer → Pull cleaned data
- Analysis Layer → Build model in R with recommenderlab
- Output Layer → Top 10 recommendations + ggplot charts
library(recommenderlab)
ratings <- read.csv("ratings.csv")
realMatrix <- as(ratings, "realRatingMatrix")
recom <- Recommender(realMatrix, method="UBCF")
pred <- predict(recom, realMatrix[1], n=10)
as(pred, "list")Project 3: Social Media Sentiment Analysis on Big Tweets
Dataset: COVID or 2025 election tweets from Kaggle
library(syuzhet)
tweets <- read.csv("cleaned_tweets.csv")
sentiment <- get_nrc_sentiment(tweets$text)
barplot(colSums(sentiment), las=2)Project 4: Customer Churn Prediction for Telecom
Dataset: Telco Customer Churn (Kaggle)
library(caret)
data <- read.csv("churn_data.csv")
model <- train(Churn ~ ., data=data, method="rf")
confusionMatrix(model)Project 5: Website Log Analysis for User Behaviour
library(ggplot2)
logs <- read.csv("hadoop_processed_logs.csv")
ggplot(logs, aes(x=Page, y=Visits)) + geom_col()Final Tips to Finish Fast
- Setup Hadoop single-node in 30 mins (see my earlier post)
- Use RStudio + Hive (all free)
- Resume line: “Built Movie Recommendation System using Hadoop HDFS + R – processed 1M ratings”
- Start with Project 2 today!
Which project are you starting first? Comment below — I’ll send full code + dataset links free!