The Apache Hadoop ecosystem is a collection of tools and components that work together to store, process, manage, and analyze very large datasets (Big Data) efficiently across clusters of computers.
1. What is Hadoop Ecosystem?
The Hadoop ecosystem refers to a set of open-source tools and frameworks built around Hadoop that help in:
Storing huge volumes of data
Processing data in parallel
Managing cluster resources
Querying and analyzing data
It allows organizations to process structured, semi-structured, and unstructured data such as logs, images, videos, and social media data.
Key idea:
Instead of using one powerful computer, Hadoop distributes data and processing across many machines.
Components of Hadoop Ecosystem
| Component | Type | Purpose |
|---|---|---|
| Hadoop Distributed File System (HDFS) | Core Component | Distributed storage system for large datasets |
| Apache MapReduce | Core Component | Processes big data using parallel computation |
| Apache Hadoop YARN | Core Component | Manages cluster resources and job scheduling |
| Apache Hive | Ecosystem Tool | SQL-like querying and data warehouse |
| Apache Pig | Ecosystem Tool | Data processing using Pig Latin scripting |
| Apache HBase | Ecosystem Tool | NoSQL database for real-time data access |
| Apache Sqoop | Ecosystem Tool | Transfers data between Hadoop and databases |
| Apache Flume | Ecosystem Tool | Collects log and streaming data |
| Apache Oozie | Ecosystem Tool | Workflow scheduler for Hadoop jobs |
| Apache ZooKeeper | Ecosystem Tool | Coordinates distributed services |

- Hive, Pig → Data processing/query
- HBase → Database
- Sqoop, Flume → Data ingestion
- Oozie → Workflow
- ZooKeeper → Coordination
1. HDFS (Hadoop Distributed File System)
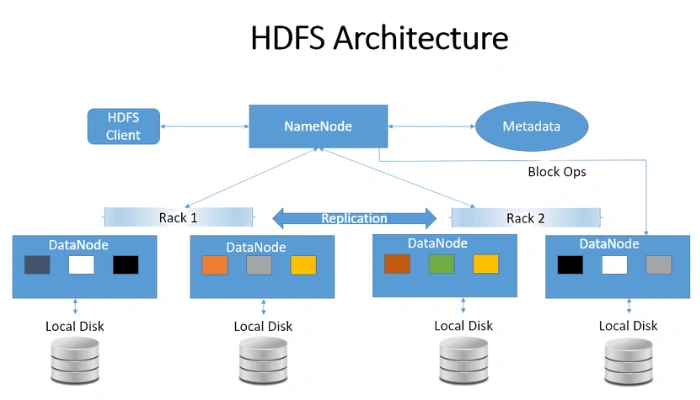
Hadoop Distributed File System is the storage layer of Hadoop.
Key Functions
Stores very large datasets
Splits files into blocks
Distributes blocks across multiple machines
Main Components
NameNode
Master server
Maintains metadata (file names, locations)
DataNode
Worker nodes
Store actual data blocks
Advantages
Fault tolerance
High scalability
Handles petabytes of data
2. MapReduce
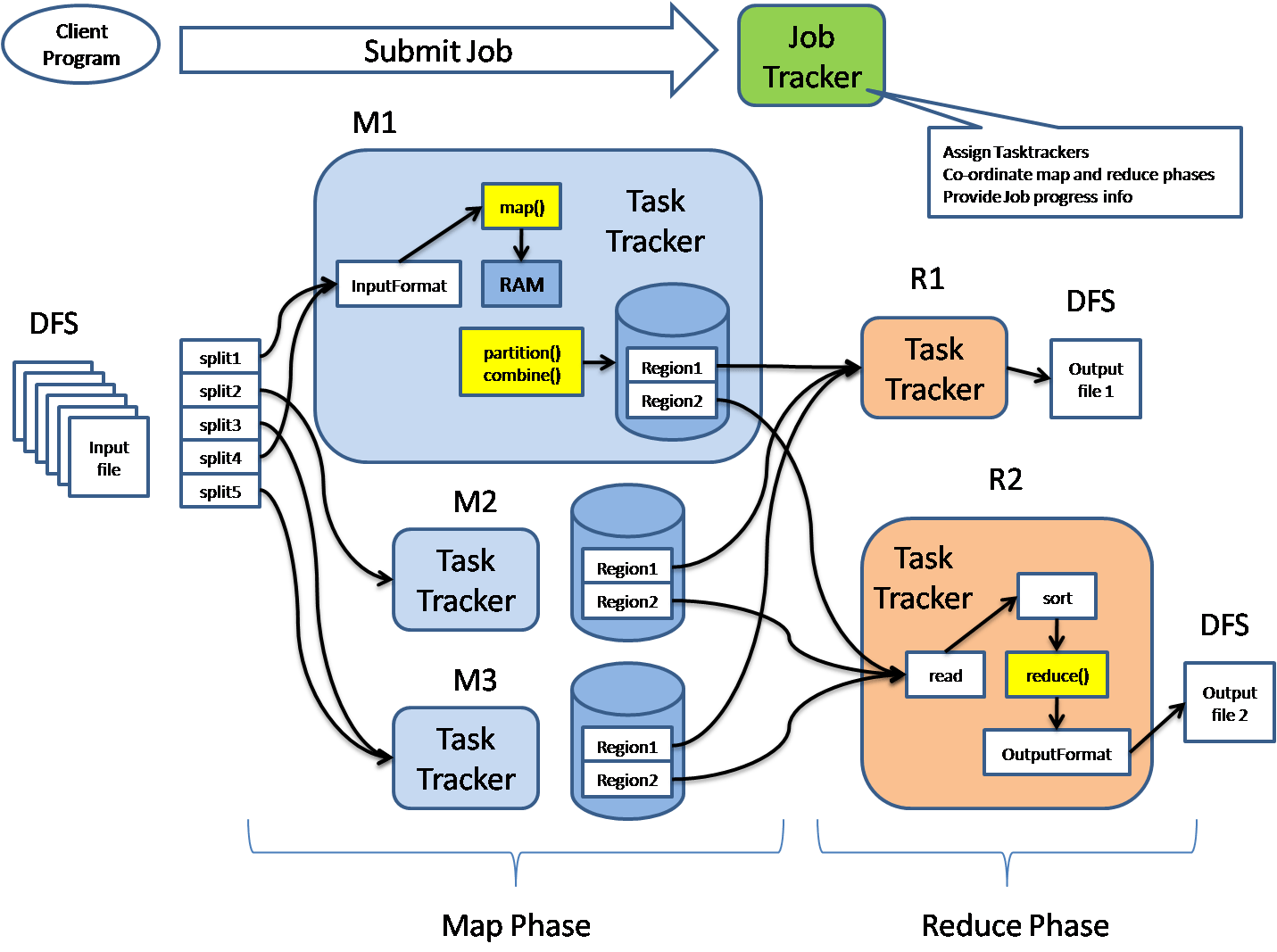
MapReduce is the processing engine of Hadoop.
It processes big data using parallel computation.
Two Main Phases
1. Map Phase
Input data is divided into smaller chunks
Mapper processes each chunk
Produces key-value pairs
Example:
Input: Big data file
Output: (word, 1)
2. Reduce Phase
Combines results from mapper
Produces final output
Example:
(word, total count)
Advantage
Massive parallel processing
Handles huge datasets efficiently
3. YARN (Yet Another Resource Negotiator)
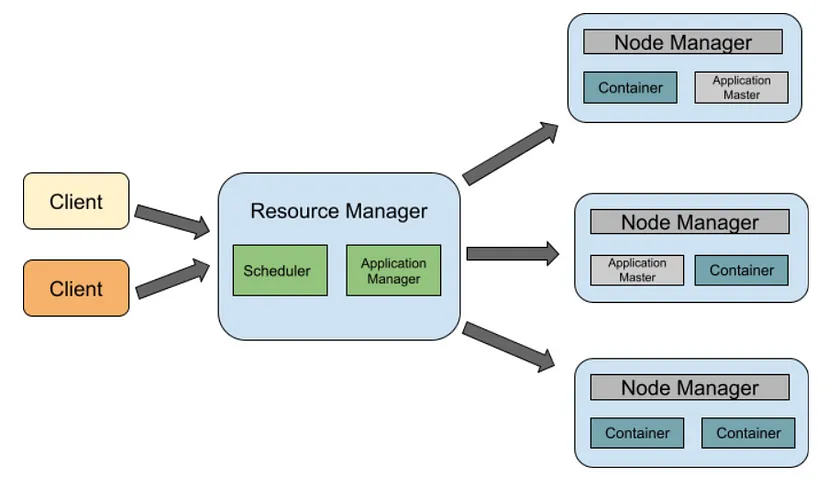
Apache Hadoop YARN manages cluster resources and job scheduling.
Main Components
Resource Manager
Global resource management
Node Manager
Runs on each node
Manages containers
Application Master
Manages execution of applications
Role
Allocates CPU and memory
Schedules jobs
Manages cluster performance
Important Hadoop Ecosystem Tools
Besides the core components, several tools support data processing.
4. Hive
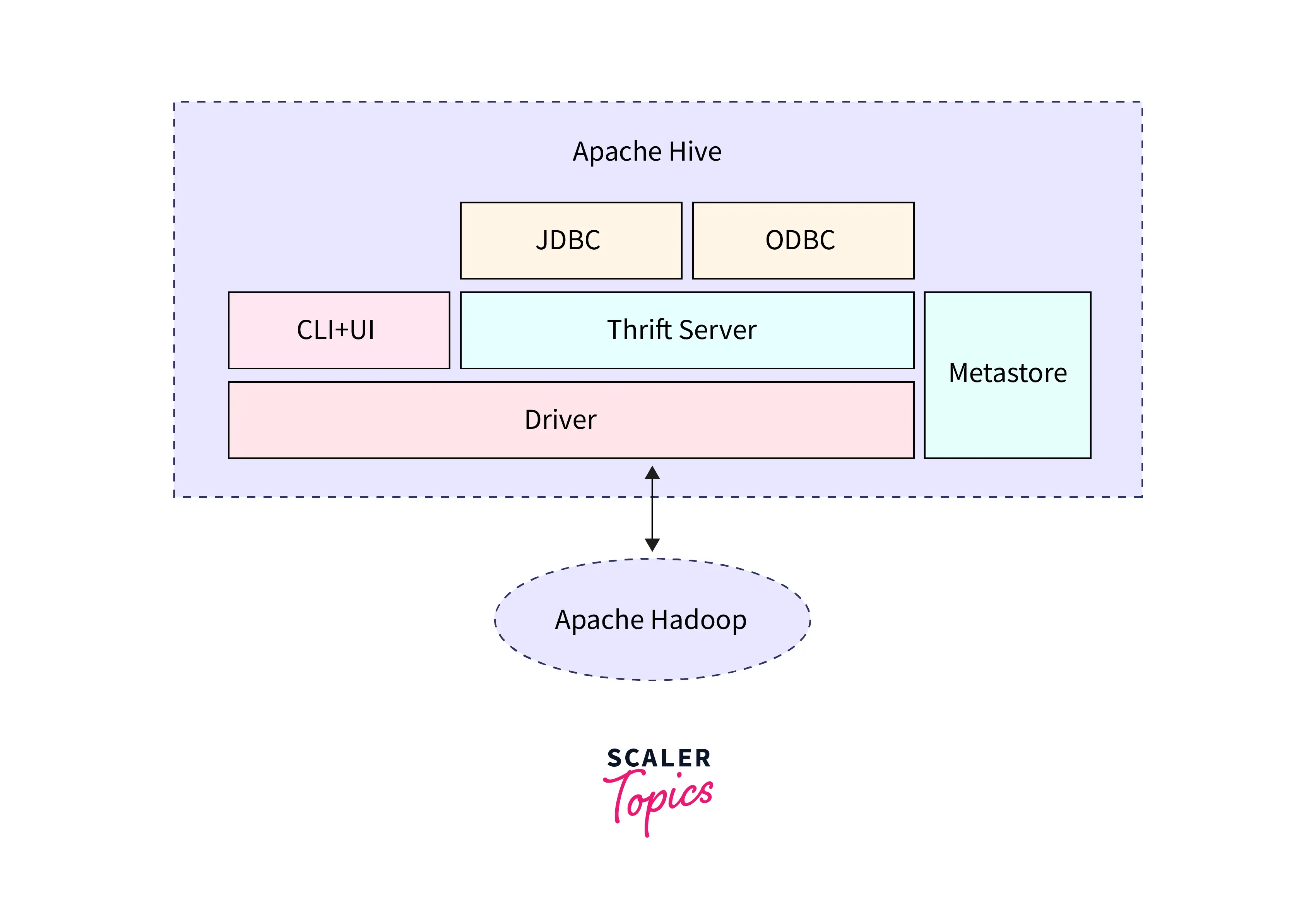
Apache Hive is a data warehouse tool used for querying large datasets stored in Hadoop.
Features
Uses SQL-like language called HiveQL
Converts queries into MapReduce jobs
Used for data analysis
Example query:
SELECT * FROM sales WHERE amount > 5000;
5. Pig
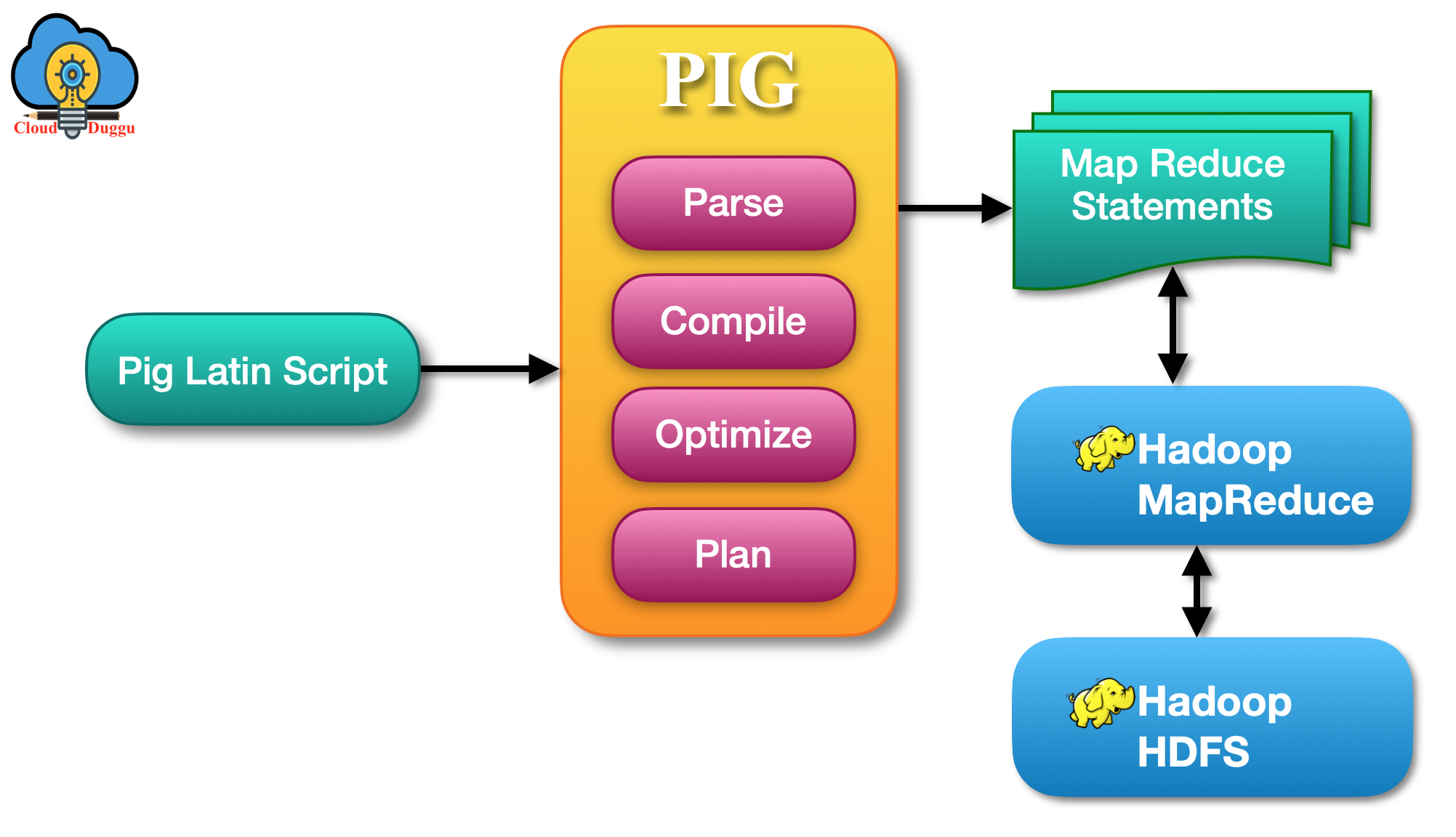
Apache Pig is a high-level scripting platform for processing large datasets.
Features
Uses Pig Latin scripting language
Simplifies MapReduce programming
Handles complex data transformations
Example:
A = LOAD 'data.txt';
B = FILTER A BY age > 20;
6. HBase
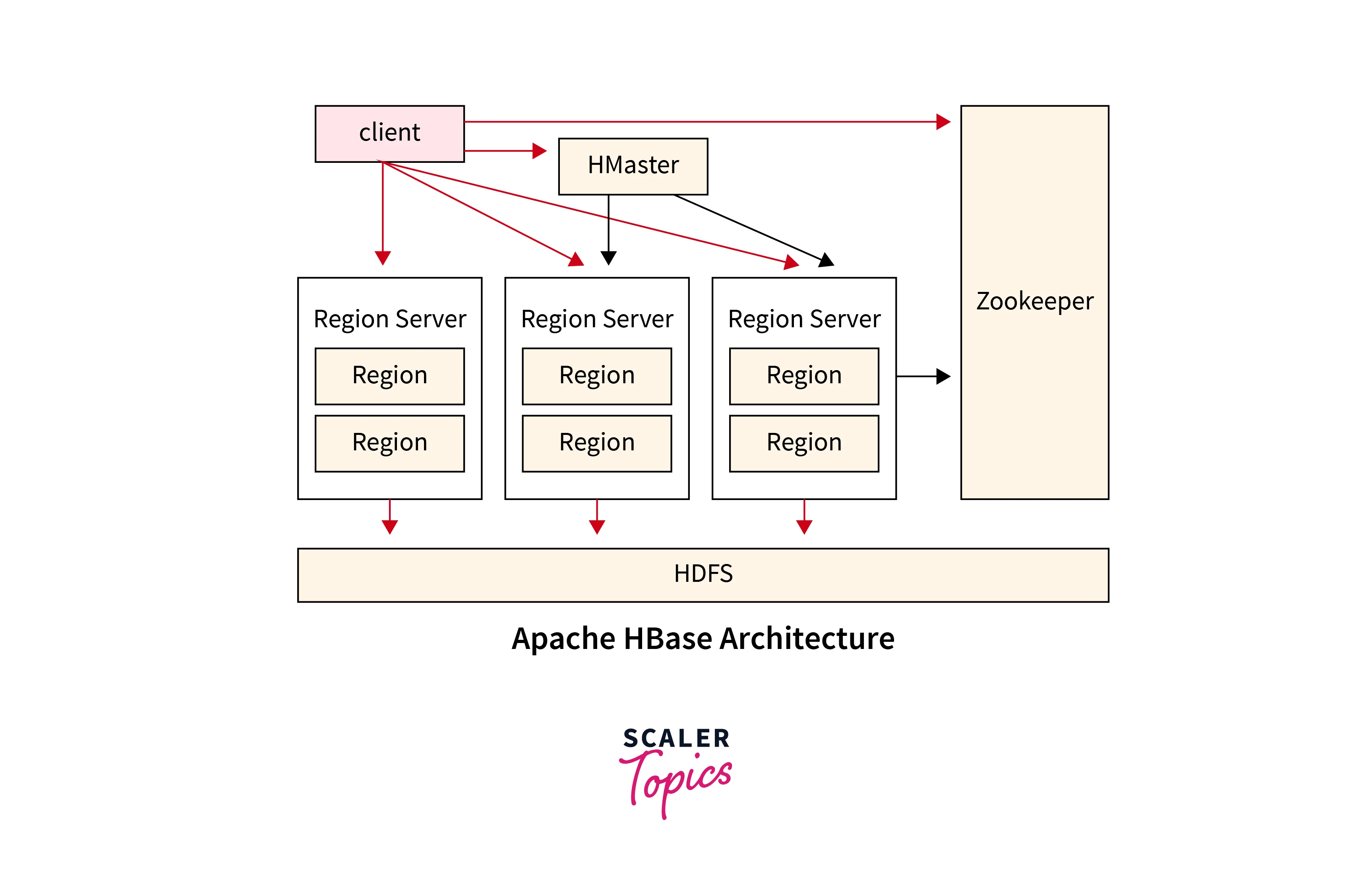
Apache HBase is a NoSQL database built on top of HDFS.
Features
Real-time read/write access
Column-oriented database
Handles billions of rows
Used for applications like:
Real-time analytics
Online data storage
Key Advantages of Hadoop Ecosystem
Scalability – Handles petabytes of data
Fault Tolerance – Data replicated across nodes
Cost Effective – Uses commodity hardware
Flexibility – Handles structured and unstructured data
Parallel Processing – Faster analysis
No comments:
Post a Comment